Mis amigos saben que me encanta el baloncesto, Linux y las cosas altamente freaks. Y esta mañana, cuando me levanté, me encontré con que uno me había compartido en el muro de Facebook esta entradade OMGUbuntu: Ver partidos de la NBA desde el terminal con NBA-Go.
¿Cómo va esto?
Bueno, lo primero es tener npm instalado instalado en vuestro equipo. Está en los repositorios de Ubuntu:
sudo apt-get update
sudo apt-get install nodejs
sudo apt-get install npm
Y una vez tengamos npm instalado vamos a instalar NBA-Go:
sudo npm install -g nba-go
El programa principalmente ofrece dos comandos: game y player (abreviados g y p). Dentro de la opción game hay dos opciones posibles: ver qué partidos hay disponibles y ver uno en concreto.
A la hora de ver los posibles tenemos las opciones date, yesterday, today y tomorrow. La primera para una fecha concreta, la segunda para los partidos de ayer, la tercera para los de hoy y la cuarta para los de mañana. Vemos ejemplos:
//fecha formato año/mes/día
$ nba-go game -d 2017/11/02
$ nba-go game --date 2017/11/02
//ayer
$ nba-go game -y
$ nba-go game --yesterday
//hoy
$ nba-go game -t
$ nba-go game --today
//mañana
$ nba-go game -T
$ nba-go game --tomorrow
Una vez listado podéis navegar con el partido, ver la información previa al juego o seguir el desarrollo del mismo con las estadísticas en directo. También podéis ver el boxscore del partido ya finalizado con toda la estadística.
Aquí os dejo un gif de la página oficial que ilustra esto:


Con el comando player tenemos tres opciones: información general, estadísticas de la temporada regular o de los playoff. Voy a usar el mismo ejemplo que en la página oficial para que cuadre con el gif que voy a usar de la misma.
//info de Curry
$ nba-go player Curry -i
$ nba-go player Curry --info
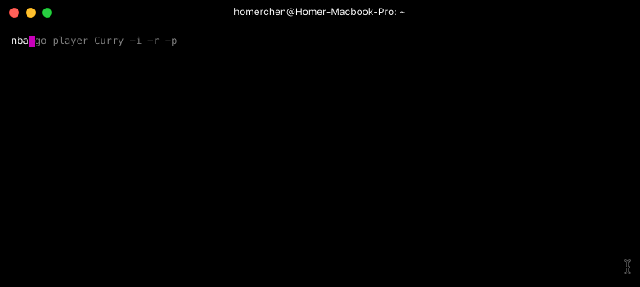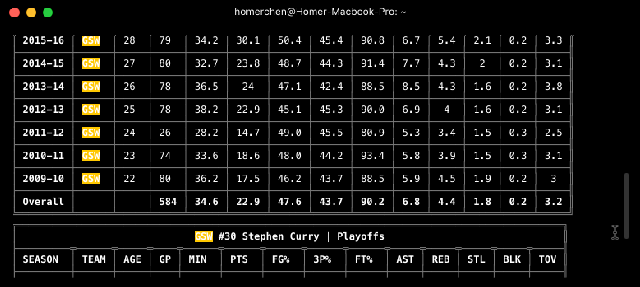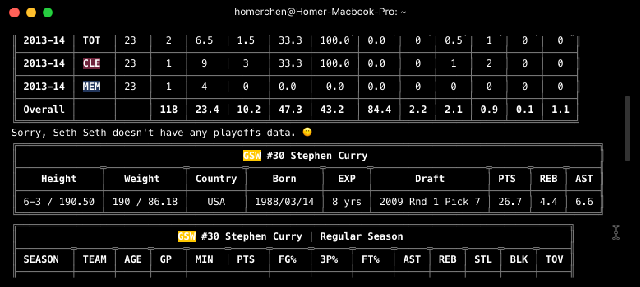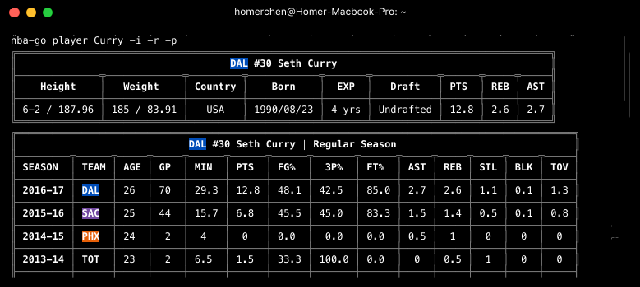
//temporada regular
$ nba-go player Curry -r
$ nba-go player Curry --regular
//eliminatorias
$ nba-go player Curry -p
$ nba-go player Curry --playoffs
//todo junto
$ nba-go player Curry -i -r -p
Os dejo por aquí el enlace al proyecto en GitHub por si queréis ver el código o si queréis clonarlo.