Hace unos años habláramos aquí de funciones lógicas en LibreOffice. En aquel entonces ya existía Google Drive pero no conocía a mucha gente que lo utilizara para sus labores ofimáticas. Hoy por hoy su uso se ha popularizado bastante, así que mi idea es repetir la misma entrada, pero con las funciones lógicas de esta hoja de cálculo que, más o menos, son similares (aunque en caso del Drive son menos que en LibreOffice, se quedan en 7). Lo primero que veremos, la lista de funciones:
- FALSO: Una función que no evalúa ningún dato, sólo devuelve el valor lógico false.
- VERDADERO: Una función que no evalúa ningún dato, sólo devuelve el valor lógico true.
- NO: Recibe una expresión lógica, su sintaxis sería NO(La_Expresión_Lógica) y devuelve el valor contrario al que recibe. Es decir, si la expresión que recibe es true la función devolverá false y viceversa.
- SI: Esta función requiere tres parámetros que son una prueba lógica, un valor a devolver si se cumple y un valor a devolver si no, aunque sólo es obligatoria la prueba lógica. Más abajo os explicaré como anidar varios. La sintaxis básica es SI(prueba lógica; valor si se cumple; valor si no).
- SI.ERROR: Función que recibe dos parámetros. Devuelve el valor del primero si este no es erróneo, en caso de que lo sea devuelve el segundo. La sintaxis es SI.ERROR(valor_a_evaluar,valor_si_error)
- O: La función recibe varios argumentos y devuelve true en caso de que alguno sea verdadero, en caso de todos sean falsos devuelve false. La sintaxis es O(expresión1,expresión2,expresión3…)
- Y: La función recibe un número variable de argumentos. En caso de que todos sean verdaderos devuelve true y caso de que alguno sea false devuelve false. La sintaxis es Y(expresión1,expresión2,expresión3…)
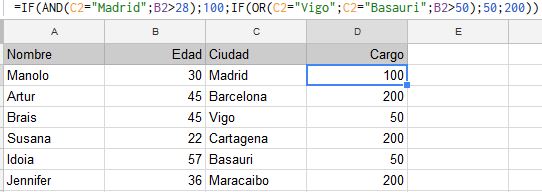
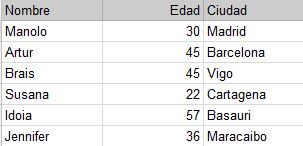
Ahora vamos con un ejemplo. Primero tenemos estos datos con nombres de usuarios, su ciudad y su edad. En base a la edad y la ciudad calcularemos un importe que tienen que pagar usando algunas de estas funciones lógicas. Las condiciones son las siguientes: si son de Madrid y mayores de 28 entonces pagan 100. Si son de Vigo, de Basauri o tienen más de 50 años entonces pagan 50. El resto pagan 200.
La función sería la siguiente:
=SI(Y(C2=«Madrid»;B2>28);100;SI(O(C2=«Vigo»;C2=«Basauri»;B2>50);50;200))
Aunque una vez la escribáis os la traducirá a la nomenclartura inglesa de las funciones:
=IF(AND(C3=«Madrid»;B3>28);100;IF(OR(C3=«Vigo»;C3=«Basauri»;B3>50);50;200))
Y el resultado de esos datos sería el siguiente: